MySql Basics
1、前言
比较少写这种文章,主要还是我 mysql 没系统化学习过,在写这篇前也只会 CRUD, 也不会 数据 库 设计😔,加上期末考正好要考 mysql,正好借这个机会重学一遍,顺便来记录一下这段学习中的一些 mysql 的操作。
2、操作数据库
==mysql 关键字 不区分大小写==(个人习惯,喜欢大写,方便区分),下文例子数据库以 kzsoft 为名。
表名与字段是关键字请带上反引号`
2.1、简单操作数据库
1、创建数据库
CREATE DATABASE IF NOT EXISTS kzsoft;
2、删除数据库
DROP DATABASE IF EXISTS kzsoft
3、使用数据库
USE kzsoft
4、查看数据库
SHOW DATABASES --查看所有的数据库 有s
2.2、数据库的数据类型
1、数值
| 类型 | 描述 | 所占字节 | 用途 |
|---|---|---|---|
| tinyint | 十分小的数据 | 1 个字节 | 一般用来当布尔值用 |
| smallint | 较小的数据 | 2 个字节 | 少用 |
| mediumint | 中等的数据 | 3 个字节 | 少用 |
| int | 标准整数 | 4 个字节 | 常用,一般都用 int |
| bigint | 较大的整数 | 8 个字节 | 少用 |
| float | 单浮点数/单精度小数 | 4 个字节 | 少用 |
| double | 双浮点数/双精度小数 | 4 个字节 | 少用 有精度问题 |
| decimal | 字符串形式的浮点数 | 不一定 | 精度要求高用 decimal (金融计算) |
2、字符串
| 类型 | 描述 | 用途 |
|---|---|---|
| char | 固定大小 0~255,不可变长度 | 存手机号等固定长度 |
| varchar | 可变字符串 0~65535 | 存可变字符串 存变量 |
| tinytext | 微型文本 2^8-1 | 能用 text 就别用这个 |
| text | 文本串 2^16-1 | 保存大文本 |
3、时间日期
| 类型 | 描述 | 用途 |
|---|---|---|
| date | YYYY-MM-DD 日期 | 存日期 |
| time | HH:mm 时间 | 存 |
| datetime | YYYY-MM-DD HH:mm | 最常用的时间格式 |
| timestamp | 时间戳形式 1970.1.1 8:00:00 到现在的毫秒数 | 但会有 2038 年问题 |
4、NULL
不要用 NULL 进行运算,结果为 NULL
2.3、字段类型
| 字段类似 | 描述 | 用途 | |
|---|---|---|---|
| Unsigned | 无符号整数 | 该列不能声明为负数 | |
| zerofill | 用 0 填充 | 不足的位数 用 0 来填充 | |
| 自增 | 自动在上一条记录+1 (默认,可设置自增大小) | 设置唯一的主键 如 id | |
| 非空 | not null | 该字段不能为 NULL | |
| 默认 | 默认值 | 不指定 则默认值 |
以下字段 是未来做项目用的,表示一个记录的存在意义
id 主键
`version` 乐观锁
is_delete 伪删除
createAt 创建时间
updateAt 修改时间
2.4、 操作表
表名与字段,尽量用``括起来(你永远不知道,你的字段名会不会和关键字重名!)
字符串 通过单引号括起来
所有语句后面加,除了最后一行
PRIMARY KEY 主键一张表只有唯一的主键
1、创建表
CREATE TABLE IF NOT EXISTS `user` (
`id` INT(10) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`username` VARCHAR(30) NOT NULL COMMENT '用户名',
`password` VARCHAR(30) NOT NULL COMMENT '密码',
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
格式如下
CREATE TABLE [IF NOT EXISTS] `表名` (
`字段名` 列类型 [属性] [索引] [注释],
`字段名` 列类型 [属性] [索引] [注释],
`字段名` 列类型 [属性] [索引] [注释],
PRIMARY KEY(` `)
)[表类型] [字符集设置] [注释]
通过上面的手动通过 sql 语句创建表,对已创建的表可通过
-
SHOW CREATE DATABASE 数据库名查看数据库的定义语句,也就是输出创建数据库的 sql 语句 -
SHOW CREATE TABLE 表名查看表的定义语句,也就是输出创建表的 sql 语句 -
DESC 表名–显示表的结构 (desc 是 describe 的缩写)2.5、数据库引擎
| MYISM | INNODB | |
|---|---|---|
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间的大小 | 较小 | 较大,约为前者 2 倍 |
| 各自优点 | 节省空间,速度快 | 安全性高,事务处理,多表多用户操作 |
MySQL 引擎在物理文件上的区别
- INNODB 在数据库表中只有一个 *.frm 文件(表结构定义文件) 以及上级目录下的 ibdata1 文件
- MYISM 对应文件 有*.frm 文件*.MYD 文件(数据文件) *.MYI 文件(索引文件)
设置数据库表的字符集编码
CHARSET=utf8
不设置的话,会是 mysql 的默认字符集编码 Latin1(不支持中文!)
在配置文件 my.ini 中配置默认编码 character-set-server=utf8
2、修改表
关键字 ALTER
--将表名user修改为account
ALTER TABLE user RENAME AS account
--添加字段 age
ALTER TABLE user ADD age INT(10)
--修改字段 (修改类型与约束)
ALTER TABLE user MODIFY age VARCHAR(10)
--修改字段 (修改字段名)
ALTER TABLE user CHANGE age age1 INT(10)
--删除字段
ALTER TABLE user DROP age
3、删除表
DROP TABLE IF RXISTS user
3、MySQL 数据管理
3.1、外键(极少用)
定义外键 key
添加约束(执行引用) references 引用
这里创建一个角色表 role,字段有 roleid,rolename,下为创建表时添加外键例子
KEY `FK_roleid` (`roleid`),
CONSTRAINT `FK_roleid` FOREIGN KEY(`roleid`) REFEREBCES `role`(`roleid`)
删除带有外键关系表时,必须先删除引用别的表(从表),再删除被引用的表(主表)
上面用户与角色关系表中,角色表就是无法直接删除,需删除用户表才可删除角色表。
可直接用 ALTER 添加外键关系
ALTER TABLE `user`
ADD CONSTRAINT `FK_roleid` FOREIGN KEY(`roleid`) REFEREBCES `role`(`roleid`)
ALTER TABLE `表名`
ADD CONSTRAINT 约束名 FOREIGN KEY(`外键`) REFEREBCES `引用表`(`引用字段`)
以上操作都是物理外键,数据库级别的外键,不建议使用!(虽然能保证数据完整性,但是寻找以及删除都是特别麻烦的,在数据量大的时候,异常痛苦,用过外键的都说坏)
3.2、DML 语言
数据库意义:数据存储,数据管理
DML:数据库操作语言
- insert
- update
- delete
3.2.1、添加(insert)
--语法
INSERT INTO 表名([字段1,字段2,字段3]) VALUES ('值1'),('值2'),('值3')
-- 插入数据
INSERT INTO `role`(`rolename`) VALUES ('管理员')
-- 插入多个数据
INSERT INTO `role`(`rolename`)
VALUES ('管理员'),('代理'),('用户')
3.2.2、更新(update)
注: 更新一定要带条件,不然就是所有数据都会更新!
--语法
UPDATE 表名 SET `字段1`='值1' WHERE 条件1
-- 修改用户名与命名
UPDATE `user` SET `username`='kuizuo',`password`='a12345678` WHERE id = 1
3.2.3、删除(delete)
DELETE 命令
--删除数据 条件
DELETE FROM `user` WHERE id = 1; --少了条件,直接全删
--删除全部数据
DELETE FROM `user`
TRUNCATE 命令(要全部删除用这个命令)
作用:完全清空一个数据库表,表的结构和索引约束不会变。
使用:TRUNCATE 表名 即可
好处:删除后,会刷新自增值(置为 0),而 DELETE 不影响自增值,为上一自增值
3.3、DQL 语言
(Data Query Language:数据查询语言)
数据库中最核心的语言,使用频率最高的语句。
完整语法
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[
FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]
]
3.3.1、指定查询
==注: 字段名也不区分大小写==
-- 查询所有字段
SELECT * FROM `user`
-- 查询指定字段
SELECT `username` FROM `user`
-- 使用别名
SELECT `username` AS 用户名 FROM `user` AS u
-- 使用函数 concat(a,b) 拼接两者字符串
SELECT CONCAT('用户名: ',`username`) AS 新用户名 FROM `user` AS u
-- 去重 distinct
SELECT DISTINCT `StudentNo` AS 学号 FROM result --去重重复数据 只显示一条
3.3.2、表达式
数据库中的表达式: 文本值,列,NULL,函数,计算表达式,系统变量…
SELECT VERSION() --查询系统版本(函数)
SELECT 100*2-123 AS 结果 --用于计算(计算表达式)
SELECT @@auto_increment_increment --查询自增的步长 变量
SELECT now() --查询当前时间
3.3.3、where 条件子句
==尽量使用英文符号==
基本运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| and && | a and b a && b | 与 |
| or || | a orb a || b | 或 |
| Not ! | not a ! a | 非 |
模糊查询
| 运算符 | 语法 | 描述 |
|---|---|---|
| BETWEEN | between … and … | 在两者之间 |
| IS NULL | a is null | 如果为 null,结果为真 |
| IS NOT NULL | a is not null | 如果不为 null,结果为真 |
| Like | a like b | a 匹配到 b,结果为真 |
| In | a in (a1,a2,a3) | 匹配 a 在 a1,a2,a3 其中之一 |
其中 like 还搭配了 %(0 到任意个字符) _(一个字符) 使用
3.3.4、联表查询(重点)
一共有 7 中 JOIN 查询
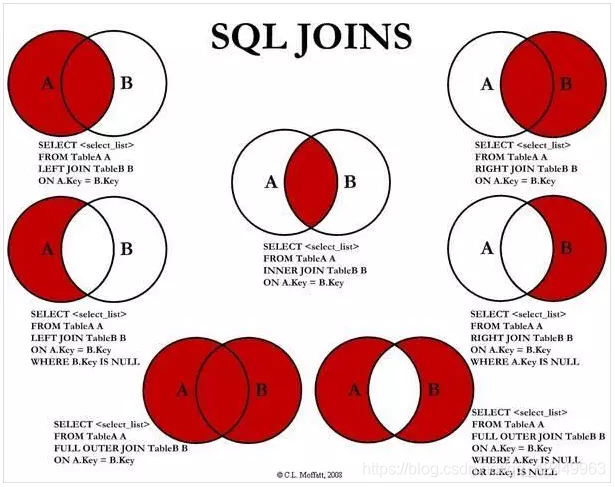
实际上用的最多的也就是以下三种,区别如下
| 操作 | 描述 |
|---|---|
| inner join | 如果表中至少有一个匹配,就返回该行 |
| left join | 会返回左表中所有数据,即使右表没有匹配 |
| right join | 会返回右表中所有数据,即使左表没有匹配 |
-- 查询用户所属角色
SELECT u.*,r.role
FROM `user` u
LEFT JOIN user_role ur ON u.id = ur.user_id
LEFT JOIN role r ON r.id = ur.user_id
WHERE
u.id = 1
-- 查询登录日志
SELECT l.login_time
FROM kz_user u
LEFT JOIN kz_login_log l ON l.user_id = u.id
3.3.5、自连接查询
自己的表和自己的表连接,核心:将一张表拆分为两张一样的表,本质还是同一张表
一张表中对应了子表,父表,并通过 pid 来标注,下为相关表结构
| menu_id | pid | menu_name |
|---|---|---|
| 1 | 0 | 首页 |
| 2 | 0 | 用户管理 |
| 3 | 2 | 用户列表 |
| 4 | 2 | 角色管理 |
| 5 | 2 | 用户角色管理 |
| 6 | 0 | 卡密管理 |
| 7 | 6 | 卡密列表 |
| 8 | 6 | 卡密购买 |
所查询的 sql 语句
SELECT a.`menu_name` AS 主菜单, b.`menu_name` AS 子菜单
FROM `menu` AS a, `menu` AS b
WHERE a.`menu_id` = b.`pid`
查询结果如下
| 主菜单 | 子菜单 |
|---|---|
| 用户管理 | 用户列表 |
| 用户管理 | 角色管理 |
| 用户管理 | 用户角色管理 |
| 卡密管理 | 卡密列表 |
| 卡密管理 | 卡密购买 |
3.3.6、分页和排序
关键字 limit 和 order by,注:limit 最后使用
排序语法: ORDER BY 字段 排序类型
升序 ASC 降序 DESC
分页语法:LIMIT 起始值,页面大小
假设当前页面需展示 10 条数据(变量 pageSize),那么
第一页数据 LiMIT 0,10 (1-1)*10
第二页数据 LiMIT 10,10 (2-1)*10
第三页数据 LiMIT 20,10 (3-1)*10
第 N 页数据 LIMIT (N-1)*pageSize,pageSize
基于这样的原理,即可实现分页,大致过程如下
首先,接收到前端发送的分页请求,page 与 pageSize,那么与之对应的数据库查询语句为
SELECT * FROM user
LIMIT (page-1)*pageSize,pageSize
总页数 = 数据总数/页面大小
3.3.7、子查询
在 where 中,条件为固定的,想根据查询当前表的结果赋值到 where 条件中,则为子查询,注:子查询多数下查询速度较慢
本质:在 where 语句中嵌套子查询语句
子查询用的少,联表查询用的多。
SELECT * FROM kz_user
WHERE id
IN (SELECT user_id FROM kz_login_log WHERE login_time<=1609104740976)
-- 查询登录时间小于1609104740976 的用户
3.3.8、分组查询
关键字 group by
注:group by 所要分组的字段,必须要在 select 中所选,且常搭配聚合函数所使用
select is_used ,count(*) as 数量 from kz_card group by is_used
-- 根据is_used 卡密是否使用分组 结果如
| 是否使用 | 数量 |
|---|---|
| 0 | 10 |
| 1 | 3 |
4、MySQL 函数
4.1、常用函数
数学运算
SELECT RAND() --返回0~1之间的随机数
字符串
SELECT CHAR_LENGTH('这是一串文本') --返回字符串长度
SELECT CONCAT('JavaScript','是世界上最好用的语言') --拼接字符串
SELECT LOWER('Kuizuo') --到小写
SELECT UPPER('Kuizuo') --到大写
时间日期
SELECT CURRENT_DATE() --获取当前日期
SELECT CURDATE() --获取当前时间 与上面等价
SELECT NOW() --获取当前时间
SELECT LOCALTIME() --本地时间
SELECT SYSDATE() --系统时间
系统
SELECT SYSTEM_USER() -- 获取当前用户
SELECT USER() -- 获取当前用户 root@localhost
SELECT VERSION() --获取当前版本 8.0.21
4.2、聚合函数(用的多)
| 函数名 | 描述 |
|---|---|
| COUNT | 计数 |
| SUM | 求和 |
| AVG | 平均值 |
| MAX | 最大值 |
| MIN | 最小值 |
| … | … |
COUNT(列) —指定列,当值为 Null 不计数
COUNT(*) —获取全部计数结果,不会忽略 NULL 值
COUNT(1) —忽略所有列,用 1 代表代码行,不会忽略 NULL 值
执行效率上: 列名为主键,count(列名)会比 count(1)快 列名不为主键,count(1)会比 count(列名)快 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*) 如果有主键,则 select count(主键)的执行效率是最优的 如果表只有一个字段,则 select count(*)最优。
使用聚合函数,常常与分组 GROUP BY 和 HAVING 结合使用。
5、事务(Transaction)
将一组 SQL 语句放在一个批次中去执行
5.1、事务原则
ACID 原则 原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性(Durability)
原子性:要么都成功,要么都失败
一致性:最终一致性,操作前与操作��后的状态一致
隔离性:针对多个用户同时操作,主要排除其他事务对本次事务的影响
持久性:事务没有提交,恢复原状,事务已提交,持久化到数据库中,已提交就不可逆。
隔离所导致的一些问题:
脏读:指一个事务读取了另外一个事务未提交的数据。
不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。
参考链接 事务 ACID 理解
5.2、MySQL 事务操作
mysql 是默认开始事务自动提交的,可通过下方设置开启关闭
SET autocommit = 0 —- 关闭
SET autocommit =1 —- 开启(默认)
-- 事务开启
START TRANSACTION --之后的sql都在同一个事务中
INSERT xxx
UPDATE xxx
-- 提交: 持久化(成功)
COMMIT
-- 回滚: 回到原来的样子(失败)
ROLLBACK
-- 事务结束
-- 了解
SAVEPOINT 保存点名 --设置一个事务的保存点
ROLLBACK TO SAVEPOINT 保存点名 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名 -- 释放保存点
6、索引
索引(Index)是帮助 MySQL 高效获取数据的数据结构。
提取句子主干,就可也得到索引的本质:索引是数据结构
6.1、索引分类
一个表中,主键索引只能有一个,唯一索引可以有多个
-
主键索引(PRIMARY KEY)
- 唯一的标识,主键不可重复,只能有一个列作为主键
-
唯一索引(UNIQUE KEY)
- 避免重复的列��出现,唯一索引可以重复,多个列,都可以标识为 唯一索引
-
常规索引(KEY/INDEX)
- 默认的,index,key 关键字来设置
-
全文索引 (FULLTEXT)
- 在特定的数据库引擎下才有
6.2、索引的使用
-- 显示所有的索引信息
SHOW INDEX FROM 表名
-- 添加一个全文索引 索引名 字段名
ALTER TABLE 表名 ADD FULLTEXT INDEX 索引名(字段名)
-- EXPLAIN 分析sql执行的状况
EXPLAIN SELECT * FROM student; -- 非全文索引
6.3、测试索引
插入 100 万数据,编写 mysql 函数
不过 mysql 的默认是不允许创建函数
在此之前需要执行一下 SET GLOBAL log_bin_trust_function_creators = 1;
DELIMITER $$ -- 写函数之前必须要写,标志
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO big(`name`,`age`,`phone`) VALUES (CONCAT('用户',i),FLOOR(RAND()*100),CONCAT('15',FLOOR(RAND()*((99999999-100000000)+100000000))));
SET i = i+1;
END WHILE;
RETURN i;
END;
SELECT mock_data(); -- 执行函数
SELECT * FROM big WHERE `name`='用户99999' --此时查询数据近0.257s
-- id_表名_字段名 索引名
-- CREATE INDEX 索引名 ON 表(字段);
CREATE INDEX id_big_name ON big(`name`);
SELECT * FROM big WHERE `name`='用户99999' --此时查询数据0.001s
索引在小数据量的时候,用处不大,但在大数据中,能得到一个非常明显的提升
6.4、索引原则
- 索引不是越多越好
- 前期完全没必要加索引,完全可以后面在添加索引
- 索引一般加在用来查询的字段,以提高查询速度
索引的数据结构
Hash 类型的索引
Btree:INNODB 的默认数据结构
有关索引的一篇文章MySQL 索引背后的数据结构及算法原理
7、角色权限管理
-- 创建用户 CREATE USER 用户名 IDENTIFIED BY ‘密码’
CREATE USER kuizuo IDENTIFIED BY '123456'
-- 修改密码 (修改当前用户)
SET PASSWORD = PASSWORD('a123456')
-- 修改密码 (修改指定用户)
SET PASSWORD FOR kuizuo= PASSWORD('a123456')
-- 重命名
RENAME USER kuizuo TO zeyu
-- 用户授权
-- CRANT ALL PRIVILEGES ON 库.表 TO 用户
-- ALL PRIVILEGES 除了给别人授权(GRANT),其他权限都有
CRANT ALL PRIVILEGES ON *.* TO kuizuo
-- 查看权限
SHOW GRANTS FOR kuizuo
SHOW GRANTS FOR root@localhost
-- root 的权限 GRANT PROXY ON ''@'' TO 'root'@'localhost' WITH GRANT OPTION
-- 撤销权限 REVOKE 权限 ON 库.表 FROM 用户
REVOKE ALL PRIVILEGES ON *.* FROM kuizuo
-- 删除用户
DROP USER kuizuo
8、数据库备份
备份方式:
-
直接拷贝物理文件(data)
-
右键选择备份导出 sql 文件(导入相当于执行 sql 语句)
-
命令行语法
导出
mysqldump -h 主机 -u 用户 -p 密码 数据库名 表名 >物理磁盘位置
导入
登录情况下,USE 选择数据库
source D:/backup.sql
或者
mysql -u 用户名 –p 密码 库名 < 备份文件
9、数据库设计
当数据库比较复杂的时候,数据库设计显得尤为重要。
软件开发中,关于数据库的设计
- 分析需求:分析业务和需要处理的数据库需求
- 概要设计:设计关系图 E-R 图
设计数据库的步骤(个人博客为例):
- 收集信息,分析需求
- 用户表(用户登录注销,用户的个人信息)
- 分类表(文章分类)
- 文章表(文章信息,作者)
- 评论表
- 友链表(友链信息)
- 自定义表(系统信息,某个关键的子,或者一些主字段) key:value
- 标识实体之间的关系
9.1、三大范式
第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项。
不然获取数据时,不好处理
第二范式(2NF):在 1NF 的基础上,非码属性必须完全依赖于候选码(在 1NF 基础上消除非主属性对主码的部分函数依赖)
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
每张表只描述一件事情
第三范式(3NF):在 2NF 基础上,任何非主属性不依赖于其它非主属性(在 2NF 基础上消除传递依赖)
第三范式需要确保数据表中的每一列数据都和主键直接相关(属性依赖主键),而不能间接相关。
规范与性能问题
关联查询的表不得超过三张表
- 在考虑规范成本与用户体验上,数据库的性能更加重要
- 故意给某些表添加一下冗余的字段,是多表查询变为单表查询。
10、数据库模型
在 Navicat 中,右键数据库,可逆向数据库到模型,模型的结果图如下
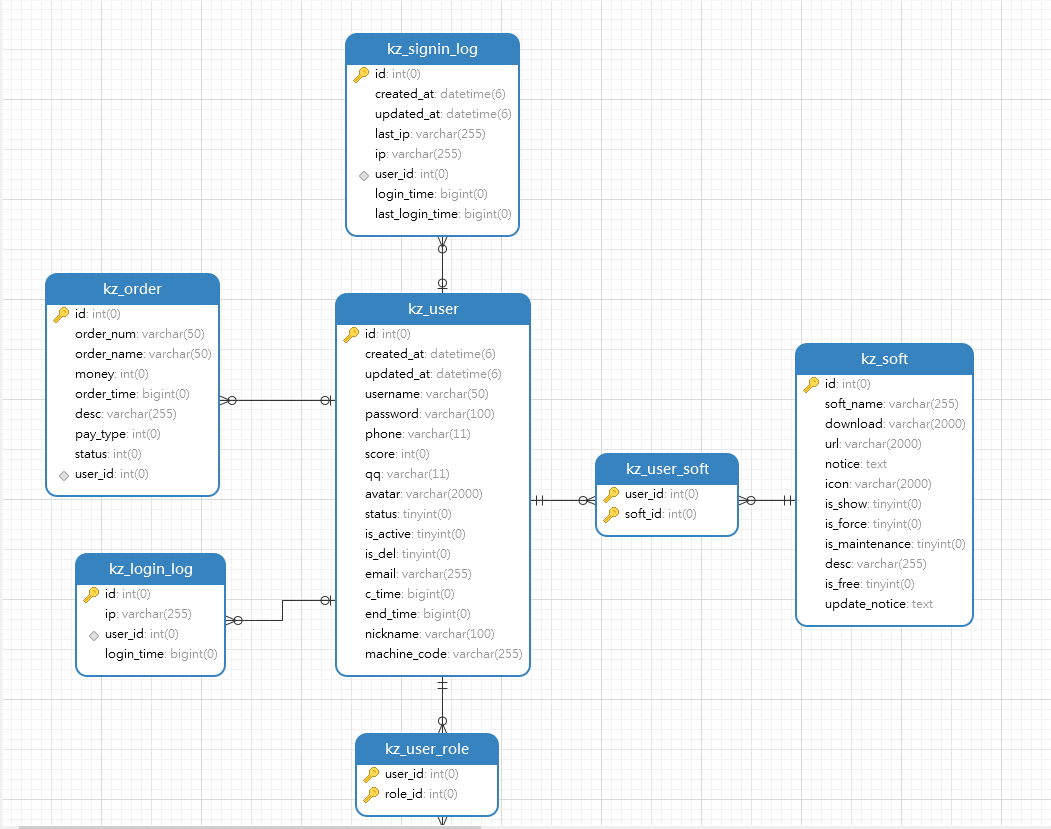
通过数据库模型,可以方便的分析该数据库中的关系,同时也可添加相应的数据等。
11、总结
简单花了两个晚上的时间刷一遍数据库的教程,并将其写成笔记总结,整体来说收获到的东西确实多,但是也有太多理论性的,例如三大范式,在考试的时候就考到过,然后我没背,但是我知道该如何规范,但就是不好表述。。。后续学习到 MongoDB 和 Redis 估计也要花点时间像这样子系统化的写个笔记,对知识巩固确实有帮助。